Boosting에서 앙상블은 약한 학습기(weak learner)라고도 하는 매우 간단한 분류기로 구성된다.
약한 학습기는 깊이가 1인 결정 트리 같이 랜덤 추측(임의 추측)보다 조금 좋은 성능을 가진 분류기이다.
Boosting의 핵심 아이디어는 분류하기 어려운 훈련 샘플에 초점을 맞추는 것이다.
잘못 분류된 훈련 샘플을 그다음 약한 학습기가 학습하여 앙상블 성능을 향상 시킨다.
Boosting Algorithm working Principle
부스팅의 초창기 방법은 중복을 허용하지 않고 훈련 데이터셋에서 랜덤 샘플을 추출하여 부분 집합을 구성한다.
1. 훈련 데이터셋 D에서 중복을 허용하지 않고 랜덤한 부분 집합을 뽑아 약한 학습기를 훈련
2. 훈련 데이터셋에서 중복을 허용하지 않고 두 번째, 랜덤한 훈련 부분 집합을 뽑고,
이전에 잘못 분류된 샘플의 50%를 더해서 두번째, 약한 학습기를 훈련
3. 훈련 데이터셋 D에서 C1, C2에서 잘못 분류한 훈련 샘플을 찾아 세 번째 약한 학습기를 훈련
4. 약한 학습기들을 다수결 투표로 연결한다.
부스팅은 배깅 모델에 비해 분산은 물론 편향도 감소시킬 수 있다.
AdaBoost, Adaptive Boosting
에이다부스트 같은 부스팅 알고리즘은 분산이 높다고 알려져 있다.(과대적합되는 경향이 있음)
에이다부스트는 원본 부스팅 방법과 달리 약한 학습기를 훈련할 때, 훈련 데이터셋 전체를 이용한다.
훈련샘플은 반복마다 가중치가 다시 부여되며, 이 앙상블은 이전 학습기의 실수를 학습하는 강력한 분류기를 만든다.
잘못 분류된 샘플에는 큰 가중치를 부여, 옳게 분류된 샘플은 가중치를 낮춘다.
Progress of AdaBoost
1. 가중치 벡터 w를 동일한 가중치로 설정한다. (합을 1로 맞춘다.)
2. m번 부스팅 반복의 j번째에서 다음을 수행한다.
a. 가중치가 부여된 약한 학습기를 훈련한다. Cj=train(X, y, w)
b. 클래스 레이블을 예측한다. y(hat)=predict(Cj, X)
c. 가중치가 적용된 에러율을 계산한다. err=w*(y(hat)!=y)
d. 학습기 가중치를 계산한다. alpha(j)=0.5log[(1-err)/err]
e. 가중치를 업데이트한다. w:=w*exp(-alpha(j)*y(hat)*y)
f. 합이 1이 되도록 가중치를 정규화한다.
3. 최종 예측을 계산한다. y(hat)=[sigma(alpha(j)*predict(Cj, X))>0]
상세한 예시:머신러닝교과서with파이썬,사이킷런,텐서플로_개정3판pg.321
사이킷런을 이용한 에이다부스트
배깅 분류기를 훈련할 때 Wine 데이터셋을 사용, base_estimator 속성으로 깊이가 1인 결정 트리를 전달하여,
트리가 500개로 구성된 AdaBoostCLassifier를 훈련
from sklearn.ensemble import AdaBoostClassifier
from sklearn.tree import DecisionTreeClassifier
tree=DecisionTreeClassifier(criterion='entropy', random_state=1, max_depth=1)
ada=AdaBoostClassifier(base_estimator=tree, n_estimators=500, learning_rate=0.1, random_state=1)
tree=tree.fit(X_train, y_train)
y_train_pred=tree.predict(X_train)
y_test_pred=tree.predict(X_test)
tree_train=accuracy_score(y_train, y_train_pred)
tree_test=accuracy_score(y_test, y_test_pred)
print('결정 트리의 훈련 정확도/테스트 정확도: %.3f/%.3f' %(tree_train, tree_test))
결정 트리의 훈련 정확도/테스트 정확도: 0.916/0.875
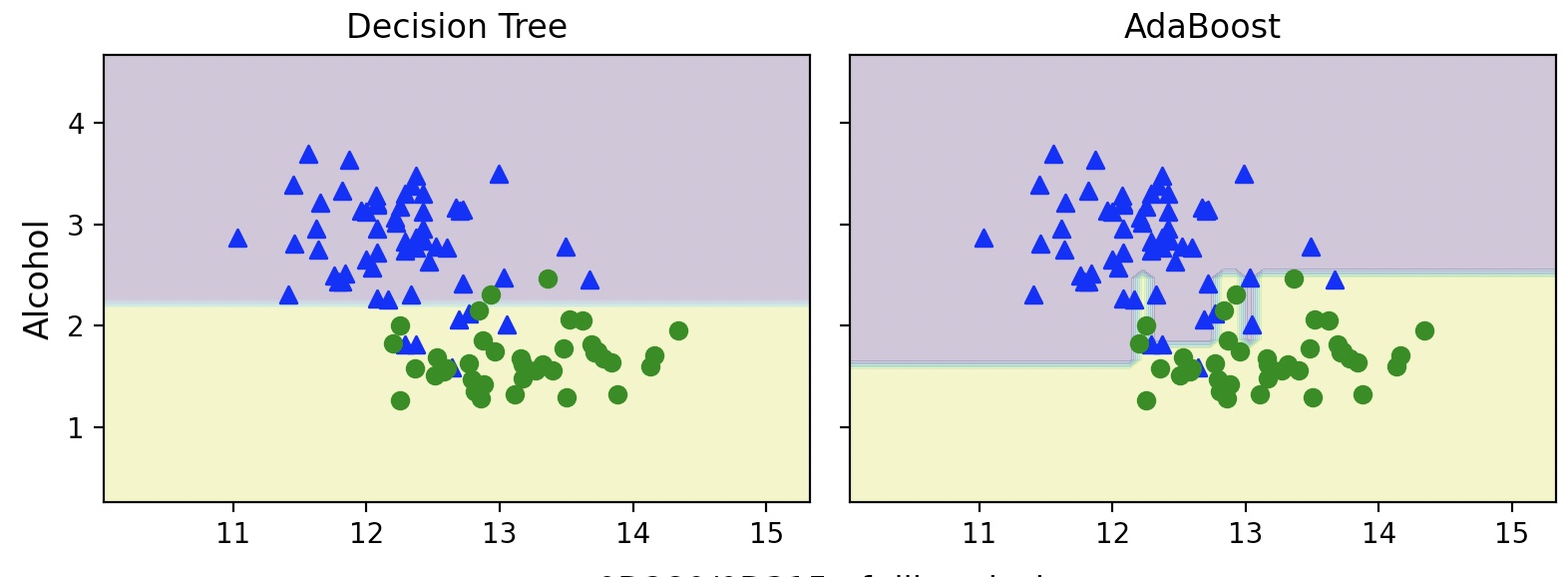
깊이가 1인 결정 트리는 가지치기가 없는 결정트리와는 반대로 훈련 데이터가 과소 적합된 것처럼 보인다.
ada=ada.fit(X_train, y_train)
y_train_pred=ada.predict(X_train)
y_test_pred=ada.predict(X_test)
ada_train=accuracy_score(y_train, y_train_pred)
ada_test=accuracy_score(y_test, y_test_pred)
print('에이다부스트의 훈련 정확도/텍스트 정확도: %.3f/%.3f' %(ada_train, ada_test))
에이다부스트의 훈련 정확도/텍스트 정확도: 1.000/0.917
에이다부스트 모델은 훈련 데이터셋의 모든 클레스 레이블을 정확하게 예측하고,
깊이가 1인 결정트리에 비해 테스트 데이터셋 성능도 더 높다.
훈련 성능과 테스트 성능 사이에 간격이 크므로 모델의 편향을 줄임으로써, 추가적인 분산이 발생했다.
테스트 데이터셋을 반복적으로 사용하여 모델을 선택하는 것은 나쁜 방법이다.
이는 일반화 성능을 매우 낙관적으로 추정하게 만든다.(높은 분산 발생)
결정 영역
import numpy as np
import matplotlib.plplot as plt
x_min=X_train[:, 0].min()-1
x_max=X_train[:. 0].max()+1
y_min=X_train[:, 1].min()-1
y_max=X_train[:, 1].max()+1
xx, yy=np.meshgrid(np.arange(x_min, x_max, 0.1), np.arange(y_min, y_max, 0.1))
f, axarr=plt.subplots(1, 2, sharex='col', sharey='row', figsize=(8, 3))
for idx, clf, tt in zip([0, 1], [tree, ada], ['Decision Tree', 'AdaBoost']):
clf.fit(X_train, y_train)
Z=clf.predict(np.c_[xx.ravel(), yy.ravel()])
Z=Z.reshape(xx.shape)
axarr[idx].contourf(xx, yy, Z, alpha=0.3)
axarr[idx].scatter(X_train[y_train==0, 0], X_train[y_train==0, 1], c='blue', marker='^')
axarr[idx].scatter(X_train[y_train==1, 0], X_train[y_train==1, 1], c='green', marker='o')
axarr[idx].set_title(tt)
axarr[0].set_ylabel('Alcohol', fontsize=12)
plt.tight_layout()
plt.text(0, -0.2, s='0D280/0D315 of diluted wines', ha='center', va='center', fontsize=12, transform=axarr[1].transAxes)
plt.show()
앙상블 기법의 앙상블 학습은 개별 분류기에 비해 계산 복잡도가 높다.
실전에서는 비교적 많지 않은 예측 성능 향상을 위해 계산 비용을 더 투자할 것인지를 주의 깊게 생각해야 한다.